第一次接触正则表达式是在今年四月的腾讯笔试,当时是一道选择题问如何判断输入的是否是 QQ 号码(即纯数字),当时是蒙了一个答案,菜鸟不会嘛 。事后自己倒专门学习了正则表达式,还做了笔记,可是平时开发倒的确是用得少,最近倒也忘了,近来又是校招的季节,自己就重新整理一篇简要入门,分享给大家的同时,自己也复习复习。
资源推荐
《正则表达式30分钟入门教程》 :请忽略这个「30分钟」,哥反正到头来还是得不断查表。
"Regular Expressions: Up and Running"" : 这个是 tutsplus 的正则表达式付费教程,由浅入深,很不错。咳咳,当年哥付费搞过一个月会员,至于这个
百度盘里是什么视频嘛,咳咳,我神马都不知道。
《正则表达式语言 - 快速参考》 : 微软 MSDN 的手册,适合参考。
《正则表达式教程》 参考文档,推荐。
什么是正则表达式
正则表达式(Regular Expression,一般简写为RegEx或者RegExp),也译为正规表示法、常规表示法,在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。from 知乎
上面那段文字是不是有点难理解,那我们就用浅显易懂的语言来解释一下。正则表达式嘛,我们平时在日常的开发中,有时候经常要有一些匹配需求,比如说:
- linux 用户经常要用到的
rm *.png命令就是删除当前目录下的所有png 格式的图片。 - 判断用户输入的 id 和密码是否符合要求(不要乱输入奇怪符号),
- 请输入你的邮箱、手机号码balabala
- 写了一个爬虫,抓取网页上的获得的数据,只需要某个列表里的一大串html 代码中某个表单 tr 里的某个 class 为 apple 的内容。
- 做报表和数据,一堆高端大气上档次亮瞎的数据呀,比如说要把2013-9-17统一替换成「13年9月17日」,咳咳,word 能解决么?反正正则是可以解决的。
总的来说,归根到底,正则表达式可以解决「查找&替换」两大需求,当然啦,根据目前我的体验,这个需求平时还是不常用的,但不管咋样,还是有用的。
正则表达式,就是利用不同的字符,由于不同的字符代表不同的含义,可以来不断精确定位我们的数据范围,然后进一步进行操作和替换。
进击之正则
学习正则,我们从最常见的字符开始。上面已经提到*号,是一个通配符,*星号所代表的就是任意的字符。比如说,我们可以使用rm *来删除文件夹中的所有文件。
杠杠的斜杠\转义字符
在正则匹配中,我们经常可以见到反斜杠\,在正则表达式中,这是转义符,一般用在两种情况:
- 一种
\符号后面跟了一个特殊的字符,指代不同类型的字符。如\d指的就是与任何十进制数字匹配。 - 另外一种情况,则是指示某些特殊符号就是原来的特殊符号,比如说我们上面所有的
*号代表所有的意思,可是如果我们要寻找就就是*这个符号本身,那我们就可以通过\*来找到,同样的,通过\\我们可以匹配字符\本身。
比如说我们luolei.org匹配的是 luolei.org ,C:\windows 匹配的是 C:\windows
元字符
元字符是正则表达式的关键,常用的元字符可以参考
最常见的比如
. 匹配除了换行符(\n)之外的任意字符
\d 匹配一个数字字符,等价于[0-9]
\w 匹配字母或者数字或者下划线或者汉字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
反义
上面我们提到了常见的元字符,可是有时候我们偏偏要找的就不是他们,那么此时我们就可以用到反义。
\D 匹配任意非数字的字符
\W 匹配任意不是字母,数字,下划线,汉字的字符
\B 匹配不是单词开头或结束的位置
[^x] 匹配除了x以外的任意字符
回到现实,我们来点实际的,比如说,我们要在下面这段数据中抓取出妹纸们的QQ号
妹纸们的联系方式(绝密!)
白富美QQ:52012345
白白美qq:520696969
捣乱的白富美QQ:520
捣乱的白富美QQ:1234567890123456
富白美QQ:abc1234
美白富PP:51696969
由常识可知,扣扣号一般都是 5-12位的,那我们可以看出只需要匹配符合 两个条件1.是QQ号不是PP 号 2.是符合5-12位的数字,
此时,我们试一试使用正则表达式QQ:\d{5,12}$,哟,匹配了,这里的{5,12},是正则表达式的限定符,表示重复的次数不少于5次,不多于12次,这里我们怎么理解呢?
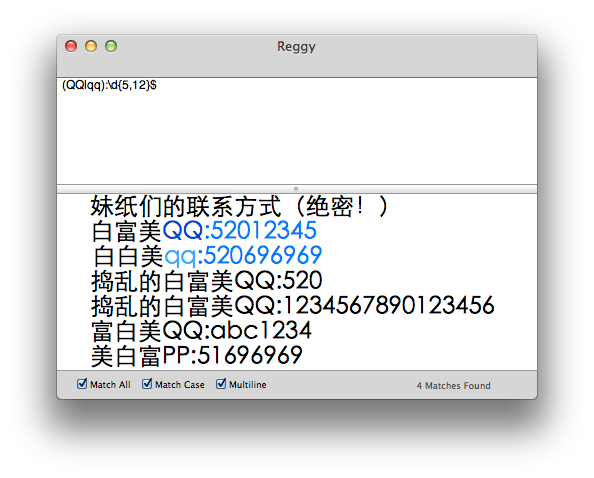
QQ:表示的是我们在数据中寻找符合QQ:的字段,找到了白富美、捣乱的白富美、富白美三都留了 QQ,接着我们要匹配的是数字\d,所以富白美开头是字母 abc 就排除了,我们还剩下两个白富美,接着我们开始寻找接下来重复了超过5次数字、但是又不超过12次数字的数据,而$则意味着必须匹配到结尾。常用的限定符有:
* 重复0次或者更多次
+ 重复1次或更多次
? 重复0次或者1次(可以理解为存在或者不存在)
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
如我们使用^\w+ 可以匹配hello_123 world luolei_ 中的hello123 (或者字符串中第一个连续字段),意思就是从^字符开头开始匹配\w字母数字下划线,直到空格停止。
字符组[ ]
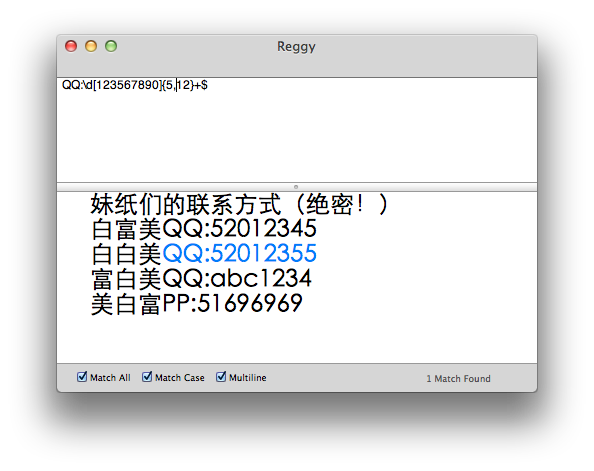
上面我们学习了一些基本的元字符,也学习了限定符,接下来我们来学习一下字符类,比如说,我是一个脑残迷信粉,我喜欢的妹纸的 QQ 号码里不能有数字4。这时候我们该怎么选呢?这个时候我们就要用到字符类方括号[ ],比如说[123567890]就是匹配不包含4的字符。
比如说QQ:\d[123567890]+$就是匹配不包含数字4妹纸的QQ。至于这段正则的含义,想必你定能悟出,有了前面的基础,只要你能理解这段正则中+$的含义就好。(注意:同样的,利用反义,我们可以通过QQ:\d[^4]{5,12}$实现一样的效果)。
分组( )和分支|
这时候,有有一个妹纸留了一个 QQ 号,可是没想到她写的是小写的 qq 而不是大写的QQ,那么此时此刻,我们该怎么办呢,意思是一样的,都是扣扣,万一错过了怎么办,此时,我们就要用到了正则表达式的分组( )和分支|功能,有点编程基础的朋友知道|一般就是或者的意思,如在 javascript 中||就是或者的意思。
if(6>5||3>5){
console.log('算你成功吧');
}
//虽说3>5是 false,可是6>5是 ture,所以依旧成功提示。
在正则中,我们也可以用|符号把不同的规则分隔开。比如说这里我们就能通过(QQ|qq):同时获取QQ:和qq:, 终于要到了妹纸的扣扣,这下该要电话号码了,号码有好多种呢,格式也不一样,以白富美为例
妹纸的电话(绝密!)
白富美联通:086-18688812345
白富美移动:15013151234
白富美座机:0755-26480888
白富美帝都:(010)12345678
白富美公司:010-88812345
我们可以看到,白富美电话众多,有手机有座机,现在比如说我们要拿白富美妹纸的所有座机号,这下蛋疼了,即有4位区号的,又有3位区号的,然后还有不同的格式,咳咳,正则在手,妹纸俺有,慢慢来。
我们观察到,有些区号是诸如(010)用(开头,那么我们就做一个判断(?,开头的数字的是一个0那我们就先来个0,可是我们后面的区号就是2个数字或者3个数,此时我们就用到分支和分组,(\d{2}|\d{3})接下来就用)右括弧又有-横杆,由于是特殊符号,我们想起了前面提到过的[]字符组方括号,来搞一个[(-]?,接下来我们知道妹纸的座机是7位或者8位的,那就再添加一个(\d{7}|\d{8}),还有一个别忘了,记得匹配到结尾哦,添加一个$,最后我们结合起来就是(?0(\d{2}|\d{3})[)-]?(\d{8}|\d{7})$,
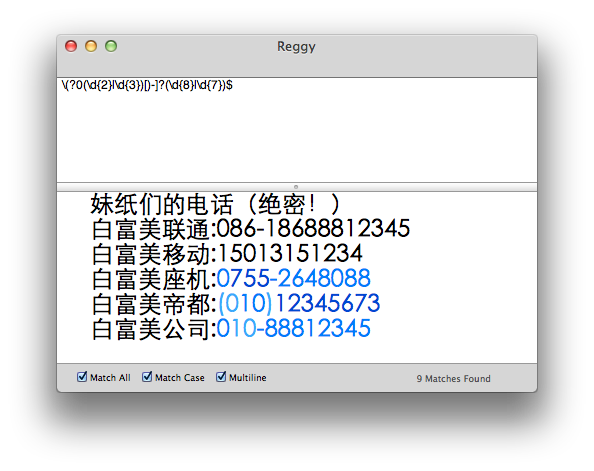
看看是不是很神奇,就这么把妹纸的座机号码给抓到了。
进阶
今天这篇分享给大家的博文,主要还是为了自己复习,正则表达式还有许多高级用法,鉴于博主水平和时间,在这里就不班门弄斧误导各位了,主要还是介绍这么一个东西给大家,让大家平时在工作、学习中遇到某些问题的时候,能够有思路怎么解决,当然,如果你真的能掌握得炉火纯青,那依旧要佩服佩服,至于到时候真的需要解决复杂的解决需求嘛,我的建议还是1.分析字符数据结构 2.查找(文档) 3.尝试。
在这里再推荐一篇从开发实例解析的正则教程